ERA5 hourly data on single levels from 1940 to present
This notebook shows how to authenticate with the DestinE API, queries and downloads ERA5 single-level reanalysis data using the DEDL HDA service, and visualizes the result with EarthKit.
To search and access DEDL data a DestinE user account is needed
Earthkit used in this context is a package provided by the European Centre for Medium-Range Weather Forecasts (ECMWF).
This notebook demonstrates how to use the HDA (Harmonized Data Access) API to access ERA5 hourly data on single levels, and how to visualize the data using the Earthkit package provided by ECMWF.
The method used to access this dataset can be applied to all the datasets hosted by the climate data store provided through HDA.
The complete list of the climate data store federated datasets provided by HDA: https://
Below the main steps covered by this tutorial.
Authenticate: How to authenticate for searching and access DEDL collections.
Order data: How to order ERA5 hourly data on single levels data through HDA.
Download data: How to download hourly data on single levels data through HDA.
Visualize: How to visualize hourly data on single levels data through Earthkit.
Authenticate¶
pip install --user --quiet --upgrade destinelabNote: you may need to restart the kernel to use updated packages.
First we import the required packages
import requests
import json
import os
import json
from getpass import getpass
from IPython.display import JSON
import destinelab as deauth
from tqdm import tqdm
import time
from urllib.parse import unquote
from time import sleepWe get an access token for the API
DESP_USERNAME = input("Please input your DESP username or email: ")
DESP_PASSWORD = getpass("Please input your DESP password: ")
auth = deauth.AuthHandler(DESP_USERNAME, DESP_PASSWORD)
access_token = auth.get_token()
if access_token is not None:
print("DEDL/DESP Access Token Obtained Successfully")
else:
print("Failed to Obtain DEDL/DESP Access Token")
auth_headers = {"Authorization": f"Bearer {access_token}"}Please input your DESP username or email: eum-dedl-user
Please input your DESP password: ········
DEDL/DESP Access Token Obtained Successfully
Response code: 200
DEDL/DESP Access Token Obtained Successfully
Order¶
Climate data store datasets need to be ordered. Below the steps to order the data of our interest.
HDA endpoint¶
HDA API is based on the Spatio Temporal Asset Catalog specification (STAC), it is convenient define a costant with its endpoint.
HDA_STAC_ENDPOINT="https://hda.data.destination-earth.eu/stac/v2"Collection discovery¶
Before querying a collection, we need its unique HDA collection ID. We can discover this ID using the HDA Discovery API by filtering on the federated provider and searching for the keywords “ERA5”, “single levels”, and “hourly data”.
response = requests.get(f"{HDA_STAC_ENDPOINT}/collections",params = {"query": '{"federation:backends": {"eq": "cop_cds"}}',"q": 'ERA5 AND "single levels" and "hourly data"'})
JSON(response.json()) From the discovery results displayed above, we can see that the collection “ERA5 hourly data on single levels from 1940 to present” has the ID EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS. We will use this identifier in all subsequent operations.
COLLECTION_ID = "EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS"Filtering¶
The “ERA5 hourly data on single levels from 1940 to present” dataset, as well as the others datasets provided by the CDS (Climate Data Store), can be subset requesting only the data of interest.
The set of parameters to subset the data are available through the HDA queryables endpoint. For this specific collection: Filter Options To understand how the HDA queryables API works you can also have a look at the queryables notebook
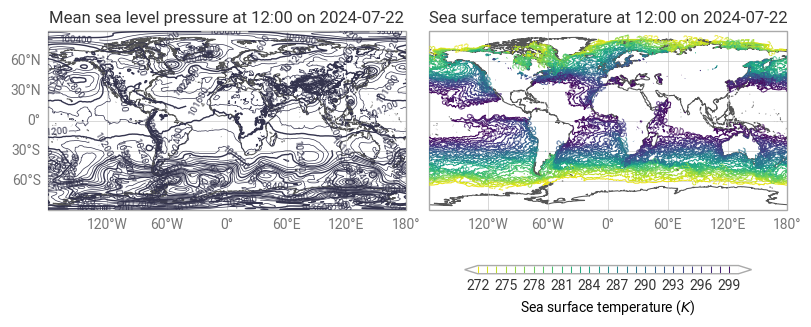
Using the information provided by the queryables endpoint, we can download the data we are interested in. In this example we will download the 2m temperature and sea surface temperature data for the hottest day in 2024, July 22nd.
Search into asynchronous datasets, as the CDS datasets are, always return a single item:
filters = {
key: {"eq": value}
for key, value in {
"ecmwf:data_format": "grib",
"ecmwf:variable": ["sea_surface_temperature","mean_sea_level_pressure"],
"ecmwf:time": ["12:00"],
"ecmwf:day": ["22"],
"ecmwf:month": ["07"],
"ecmwf:year": ["2024"],
"ecmwf:product_type": ["reanalysis"],
"ecmwf:download_format": "unarchived"
}.items()
}
response = requests.post(f"{HDA_STAC_ENDPOINT}/search", headers=auth_headers, json={
"collections": ["EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS"],
"query": filters
})
if(response.status_code!= 200):
(print(response.text))
response.raise_for_status()
product = response.json()["features"][0]
product{'type': 'Feature',
'assets': {},
'id': 'ERA5_SL_ORDERABLE_169fb56921429a47db43787af6f9b3e37610d57d',
'geometry': {'type': 'Polygon',
'coordinates': [[[180.0, -90.0],
[180.0, 90.0],
[-180.0, 90.0],
[-180.0, -90.0],
[180.0, -90.0]]]},
'bbox': [-180.0, -90.0, 180.0, 90.0],
'collection': 'EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS',
'stac_version': '1.1.0',
'properties': {'datetime': '2024-07-22T12:00:00.000Z',
'end_datetime': '2024-07-22T12:00:00.000Z',
'start_datetime': '2024-07-22T12:00:00.000Z',
'title': 'ERA5_SL_ORDERABLE_169fb56921429a47db43787af6f9b3e37610d57d',
'ecmwf:data_format': 'grib',
'ecmwf:dataset': 'reanalysis-era5-single-levels',
'ecmwf:day': ['22'],
'ecmwf:download_format': 'unarchived',
'ecmwf:month': ['07'],
'ecmwf:product_type': ['reanalysis'],
'ecmwf:time': ['12:00'],
'ecmwf:variable': ['mean_sea_level_pressure', 'sea_surface_temperature'],
'ecmwf:year': ['2024'],
'order:status': 'orderable',
'federation:backends': ['cop_cds'],
'providers': [{'name': 'cop_cds', 'roles': ['host']}]},
'stac_extensions': ['https://stac-extensions.github.io/order/v1.1.0/schema.json'],
'links': [{'rel': 'retrieve',
'type': 'application/geo+json',
'href': 'https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS/order',
'method': 'POST',
'title': 'Retrieve',
'body': {'data_format': 'grib',
'day': ['22'],
'download_format': 'unarchived',
'month': ['07'],
'product_type': ['reanalysis'],
'time': ['12:00'],
'variable': ['mean_sea_level_pressure', 'sea_surface_temperature'],
'year': ['2024']}},
{'rel': 'collection',
'type': 'application/json',
'href': 'https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS',
'title': 'ERA5 hourly data on single levels from 1940 to present'},
{'rel': 'self',
'type': 'application/geo+json',
'href': 'https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS/items/ERA5_SL_ORDERABLE_169fb56921429a47db43787af6f9b3e37610d57d',
'title': 'Original item link'}]}The single item returned (above) contains:
The product id: “ERA5_SL_ORDERABLE_...”, that is a placeholder, its name contains the term “ORDERABLE”.
The order:status that indicates that the product is “orderable”
Request params used for the order extracted from the search result:
ecmwf:variables: “2m_temperature”, “sea_surface_temperature”
ecmwf:day:“22”
ecmwf:dataset:“reanalysis-era5-single-levels”
ecmwf:month:“7”
ecmwf:data_format:“grib”
ecmwf:time:“12:00”
ecmwf:year:“2024”
ecmwf:product_type:“reanalysis”
link = next((l for l in product.get('links', []) if l.get("rel") == "retrieve"), None)
if link:
href = link.get("href")
body = link.get("body")
print("order endpoint:", href)
print("order body:")
print(json.dumps(body, indent=4))
else:
print(f"No link with rel='{target_rel}' found")
order endpoint: https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS/order
order body:
{
"data_format": "grib",
"day": [
"22"
],
"download_format": "unarchived",
"month": [
"07"
],
"product_type": [
"reanalysis"
],
"time": [
"12:00"
],
"variable": [
"mean_sea_level_pressure",
"sea_surface_temperature"
],
"year": [
"2024"
]
}
Order data¶
We have now all the information to order the data.
From the search results we know that the product is orderable and offline, we then need to order the product we searched for.
response = requests.post(href, json=body, headers=auth_headers)
if response.status_code != 200:
print(response.content)
response.raise_for_status()
ordered_item = response.json()
product_id = ordered_item["id"]
storage_tier = ordered_item["properties"].get("storage:tier", "online")
order_status = ordered_item["properties"].get("order:status", "unknown")
federation_backend = ordered_item["properties"].get("federation:backends", [None])[0]
print(f"Product ordered: {product_id}")
print(f"Provider: {federation_backend}")
print(f"Order status: {order_status}")Product ordered: 62434bc8-29eb-47c3-80ad-e0c77bbb844a
Provider: cop_cds
Order status: ordered
Poll the API until product is ready¶
We request the product itself to get an update of its status.
#timeout and step for polling (sec)
TIMEOUT = 300
STEP = 1
ORDER_STATUS = "succeeded"
self_url = f"{HDA_STAC_ENDPOINT}/collections/{COLLECTION_ID}/items/{product_id}"
item = {}
for i in range(0, TIMEOUT, STEP):
print(f"Polling {i + 1}/{TIMEOUT // STEP}")
response = requests.get(self_url, headers=auth_headers)
response.raise_for_status()
item = response.json()
print(item["properties"].get("order:status"))
status = item["properties"].get("order:status")
if status == ORDER_STATUS:
download_url = item["assets"]["downloadLink"]["href"]
print("Product is ready to be downloaded.")
print(f"Asset URL: {download_url}")
break
sleep(STEP)
else:
order_status = item["properties"].get("order:status", "unknown")
print(f"We could not download the product after {TIMEOUT // STEP} tries. Current order status is {order_status}")
Polling 1/300
ordered
Polling 2/300
ordered
Polling 3/300
ordered
Polling 4/300
ordered
Polling 5/300
ordered
Polling 6/300
succeeded
Product is ready to be downloaded.
Asset URL: https://hda-download.leonardo.data.destination-earth.eu/data/cop_cds/EO.ECMWF.DAT.REANALYSIS_ERA5_SINGLE_LEVELS/62434bc8-29eb-47c3-80ad-e0c77bbb844a/downloadLink
Download¶
response = requests.get(download_url, stream=True, headers=auth_headers)
response.raise_for_status()
content_disposition = response.headers.get('Content-Disposition')
total_size = int(response.headers.get("content-length", 0))
if content_disposition:
filename = content_disposition.split('filename=')[1].strip('"')
filename = unquote(filename)
else:
filename = os.path.basename(url)
# Open a local file in binary write mode and write the content
print(f"downloading {filename}")
with tqdm(total=total_size, unit="B", unit_scale=True) as progress_bar:
with open(filename, 'wb') as f:
for data in response.iter_content(1024):
progress_bar.update(len(data))
f.write(data)downloading cafda6d0c1abaf2aa520e84eda61a796.grib
3.58MB [00:00, 12.1MB/s]
import earthkit.data
import earthkit.plots
import earthkit.regrid
data = earthkit.data.from_source("file", filename)
earthkit.plots.quickplot(data)<earthkit.plots.components.figures.Figure at 0x7f0d6b2796d0>