Weather-Induced Extremes DT Parameter Plotter Tutorial
This notebook shows how to select, request, and download Digital Twin for Weather-Induced Extremes data from the DestinE Data Lake (DEDL HDA), including user-defined parameter, date, and level selection, followed by secure authentication, API querying, and visualization using EarthKit.
To search and access DEDL data a DestinE user account is needed
To search and access DT data an upgraded access is needed.
Earthkit used in this context is a package provided by the European Centre for Medium-Range Weather Forecasts (ECMWF).
This notebook demonstrates how to access Extreme DT data via HDA (Harmonized Data Access) API.
The DestinE Digital Twin for Weather-Induced Extremes (Extremes DT) supports responding and adapting to extreme events in a changing world by providing a capability to produce tailored simulations.
Extreme DT data includes a wide range of atmospheric and land-surface parameters. The Data Lake’s Harmonised Data Access (HDA) service provides access to these datasets through STAC APIs, leveraging the Polytope API for efficient data retrieval.
This notebook guides you through the available parameters and configuration options, helping you construct appropriate HDA requests to access and visualize Extreme DT data relevant to your specific use case.
The workflow shown in this notebook, illustrated below, begins with STAC-based discovery of collections and parameters, continues by refining the search using the Queryables endpoint, and concludes with the execution of the appropriate Polytope request through HDA.

Below the main steps covered by this tutorial.
Setup: Import the required libraries and define some function.
Parameter Selection - Discover query parameters: How to select the desired Extreme DT variable among the ones available.
Search Refinement via the Queryables API - Discover query parameters: How to refine a search using the Queryables API.
Order and Download - Order and Access Extreme DT data: How to order and download Extreme DT data.
Plot: How to visualize selected data through Earthkit.
Setup¶
pip install --user --quiet --upgrade destinelabNote: you may need to restart the kernel to use updated packages.
Import the Climate DT parameters & scenarios dictionary and all the required packages.
import destinelab as deauth
import ipywidgets as widgets
import json
import importlib.metadata
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
import os
import re
from getpass import getpass
from tqdm import tqdm
import time
from urllib.parse import unquote
from IPython.display import JSON
from datetime import datetime, timedelta
import pandas as pd
from IPython.display import display, HTMLdefine some useful constants
HDA_STAC_ENDPOINT="https://hda.data.destination-earth.eu/stac/v2"
print("STAC endpoint: ", HDA_STAC_ENDPOINT)STAC endpoint: https://hda.data.destination-earth.eu/stac/v2
HDA_DISCOVERY_ENDPOINT = HDA_STAC_ENDPOINT+'/collections'
print("HDA discovery endpoint: ", HDA_DISCOVERY_ENDPOINT)HDA discovery endpoint: https://hda.data.destination-earth.eu/stac/v2/collections
COLLECTION_ID = "EO.ECMWF.DAT.DT_EXTREMES"
EXTREMES_QUERYABLES_ENDPOINT = HDA_STAC_ENDPOINT+'/collections/'+COLLECTION_ID+'/queryables'
print("HDA queryables endpoint for the Extremes DT collection: ", EXTREMES_QUERYABLES_ENDPOINT)HDA queryables endpoint for the Extremes DT collection: https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.DT_EXTREMES/queryables
define some useful functions to manage the parameters selection done by the widgets.
#show the info of the selected variable
def show_variable_info(change):
q = combo.value.lower()
with out:
out.clear_output()
# Find all keys containing the query
matches = [k for k in keys if q in k.lower()]
# Print matching keys
for k in matches:
print(k)
# Check for exact match among the matches
exact_matches = [k for k in matches if k.lower() == q]
# Trigger variable info if:
# - only one match exists
# - OR multiple matches exist but one is an exact match
if len(matches) == 1 or len(exact_matches) == 1:
selected_key = exact_matches[0] if exact_matches else matches[0]
var = collection_json["cube:variables"][selected_key]
print(exact_matches, "\n" + var.get("description", "").strip(), "\n")
attrs = var.get("attrs", {})
var_sel["name"] = selected_key
var_sel["parameter_ID"] = attrs.get("parameter_ID")
var_sel["levtype"] = attrs.get("levtype")
var_sel["time"] = attrs.get("time")
var_sel["levelist"] = attrs.get("levelist")
print(json.dumps(attrs, indent=2))
print("\nSaved selection:")
print({k: var_sel[k] for k in ["name","parameter_ID","levtype","time"]})
#shows levtype selection
def refresh_levtype(change):
var_sel["levtype"] = levtype_dd.value
with out_levtype_dd:
out_levtype_dd.clear_output()
print(f"Variable: {var_sel.get('name')}")
print(f"Levtype: {var_sel.get('levtype')}")
#shows selection
def refresh_step_levels(_=None):
# Persist step
if steps_dd is not None:
var_sel["steps"] = steps_dd.value
else:
var_sel.pop("steps", None)
# Persist selected levels as a list (if shown)
if levels_ms is not None:
var_sel["levels"] = list(levels_ms.value)
else:
var_sel.pop("levels", None)
with out:
out.clear_output()
print(f"Variable: {var_sel.get('name')}")
print(f"Levtype: {var_sel.get('levtype')}")
if "steps" in var_sel:
print(f"Selected step: {var_sel['steps']}")
if "levels" in var_sel:
print(f"Selected levels: {var_sel['levels'] if var_sel['levels'] else '(none)'}")
if levels_ms is None:
print("No levels selector (no 'levelist' provided).")
if steps_dd is None:
print("No levels selector (no 'steps' provided).")Parameter Selection - Discover query parameters¶
The DT Extremes collection ID can be discovered through the collections discovery endpoint using a free-text search.
DT Extremes parameters available via HDA can be obtained by inspecting the metadata of the Extremes DT collections.
Collection discovery¶
Let’s start discoverying the relevant info, name id and short description, about the Extremes DT HDA collection.
URL = HDA_DISCOVERY_ENDPOINT
params = {
"q": '"Extremes DT"', #Free-text search, keep the quotes to search the phrase
}
resp = requests.get(URL, params=params, timeout=60)
resp.raise_for_status()
discovery_json = resp.json()
collections = discovery_json.get("collections", [])
COLLECTION_ID=collections[0]["id"]
# Build table with id and title
rows = []
for c in discovery_json.get("collections", []):
interval = c.get("extent").get("temporal").get("interval")
start, end = interval[0]
start_date = start.split("T")[0]
end_date = end.split("T")[0]
rows.append({
"HDA - Extreme DT collection title": c.get("title"),
"HDA - Extreme DT collection ID": c.get("id") ,
"Description": c.get("dedl:short_description")
})
df = pd.DataFrame(rows).reset_index(drop=True)
HTML(df.to_html(index=False))
Parameter search via collection metadata.¶
Using the collection name we can discover the avaiable parameters/variables for the selected collection.
Type in the text box to narrow down the list of available parameters. Once the parameter details appear, that parameter will be selected for your data request.
collection_json = requests.get(
HDA_STAC_ENDPOINT+"/collections/"+COLLECTION_ID,
).json()
keys = sorted(collection_json["cube:variables"])
print("\nType in the Combobox to narrow the list and select a variable for your data request.\n")
combo =widgets.Combobox(
placeholder="Start typing…",
options=keys,
description="Variable:",
ensure_option=False,
)
out =widgets.Output()
# container to reuse later
var_sel = {"parameter_ID": None, "levtype": None, "time": None, "name": None}
combo.observe(show_variable_info, names="value")
display(combo, out)
show_variable_info(None)Search Refinement via the Queryables API - Discover query parameters¶
Using the HDA queryables endpoint we can find all the filters needed to search and order Extremes DT data for the selected parameters.
The result of the following request will show, in the properties section, all the available filters for the Extremes DT collection and their possible values.
response = requests.get(EXTREMES_QUERYABLES_ENDPOINT)
#JSON(response.json())
print(json.dumps(response.json(),indent=2)){
"$id": "https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.DT_EXTREMES/queryables",
"$schema": "https://json-schema.org/draft/2019-09/schema",
"additionalProperties": false,
"description": "Queryable names for DEDL HDA STAC API.",
"properties": {
"ecmwf:class": {
"const": "d1",
"default": "d1",
"title": "class",
"type": "string"
},
"ecmwf:dataset": {
"const": "extremes-dt",
"default": "extremes-dt",
"title": "dataset",
"type": "string"
},
"ecmwf:date": {
"enum": [
"20260702",
"20260703",
"20260704",
"20260705",
"20260706",
"20260707",
"20260708",
"20260709",
"20260710",
"20260711",
"20260712",
"20260713",
"20260714",
"20260715",
"20260716",
"20260717",
"20260718",
"20260719",
"20260720",
"20260721",
"20260722",
"20260723",
"20260724",
"20260725",
"20260726",
"20260727"
],
"title": "date",
"type": "string"
},
"ecmwf:expver": {
"const": "0001",
"default": "0001",
"title": "expver",
"type": "string"
},
"ecmwf:levelist": {
"items": {
"enum": [
"1",
"10",
"100",
"1000",
"150",
"2",
"20",
"200",
"250",
"3",
"30",
"300",
"400",
"5",
"50",
"500",
"7",
"70",
"700",
"850",
"925"
],
"type": "string"
},
"title": "levelist",
"type": "array"
},
"ecmwf:levtype": {
"enum": [
"hl",
"pl",
"sfc"
],
"title": "levtype",
"type": "string"
},
"ecmwf:param": {
"items": {
"enum": [
"129",
"130",
"131",
"132",
"133",
"134",
"136",
"137",
"140221",
"140229",
"140230",
"140231",
"140232",
"142",
"144",
"151",
"157",
"164",
"165",
"166",
"167",
"168",
"169",
"175",
"176",
"177",
"178",
"179",
"180",
"181",
"205",
"228",
"228029",
"228050",
"228058",
"228216",
"228218",
"228219",
"228221",
"228235",
"235",
"260015",
"3020",
"31",
"34",
"78"
],
"type": "string"
},
"title": "param",
"type": "array"
},
"ecmwf:step": {
"items": {
"enum": [
"0",
"0-1",
"0-6",
"1",
"1-2",
"10",
"10-11",
"11",
"11-12",
"12",
"12-13",
"12-18",
"13",
"13-14",
"14",
"14-15",
"15",
"15-16",
"16",
"16-17",
"17",
"17-18",
"18",
"18-19",
"18-24",
"19",
"19-20",
"2",
"2-3",
"20",
"20-21",
"21",
"21-22",
"22",
"22-23",
"23",
"23-24",
"24",
"24-25",
"24-30",
"25",
"25-26",
"26",
"26-27",
"27",
"27-28",
"28",
"28-29",
"29",
"29-30",
"3",
"3-4",
"30",
"30-31",
"30-36",
"31",
"31-32",
"32",
"32-33",
"33",
"33-34",
"34",
"34-35",
"35",
"35-36",
"36",
"36-37",
"36-42",
"37",
"37-38",
"38",
"38-39",
"39",
"39-40",
"4",
"4-5",
"40",
"40-41",
"41",
"41-42",
"42",
"42-43",
"42-48",
"43",
"43-44",
"44",
"44-45",
"45",
"45-46",
"46",
"46-47",
"47",
"47-48",
"48",
"48-49",
"48-54",
"49",
"49-50",
"5",
"5-6",
"50",
"50-51",
"51",
"51-52",
"52",
"52-53",
"53",
"53-54",
"54",
"54-55",
"54-60",
"55",
"55-56",
"56",
"56-57",
"57",
"57-58",
"58",
"58-59",
"59",
"59-60",
"6",
"6-12",
"6-7",
"60",
"60-61",
"60-66",
"61",
"61-62",
"62",
"62-63",
"63",
"63-64",
"64",
"64-65",
"65",
"65-66",
"66",
"66-67",
"66-72",
"67",
"67-68",
"68",
"68-69",
"69",
"69-70",
"7",
"7-8",
"70",
"70-71",
"71",
"71-72",
"72",
"72-73",
"72-78",
"73",
"73-74",
"74",
"74-75",
"75",
"75-76",
"76",
"76-77",
"77",
"77-78",
"78",
"78-79",
"78-84",
"79",
"79-80",
"8",
"8-9",
"80",
"80-81",
"81",
"81-82",
"82",
"82-83",
"83",
"83-84",
"84",
"84-85",
"84-90",
"85",
"85-86",
"86",
"86-87",
"87",
"87-88",
"88",
"88-89",
"89",
"89-90",
"9",
"9-10",
"90",
"90-91",
"90-96",
"91",
"91-92",
"92",
"92-93",
"93",
"93-94",
"94",
"94-95",
"95",
"95-96",
"96"
],
"type": "string"
},
"title": "step",
"type": "array"
},
"ecmwf:stream": {
"enum": [
"oper",
"wave"
],
"title": "stream",
"type": "string"
},
"ecmwf:time": {
"default": "0000",
"items": {
"const": "0000",
"type": "string"
},
"title": "time",
"type": "array"
},
"ecmwf:type": {
"const": "fc",
"default": "fc",
"title": "type",
"type": "string"
},
"datetime": {
"title": "Date and Time",
"description": "The searchable date/time of the assets, in UTC (Formatted in RFC 3339) ",
"type": [
"string",
"null"
],
"format": "date-time",
"pattern": "(\\+00:00|Z)$"
}
},
"required": [
"ecmwf:date",
"ecmwf:levelist",
"ecmwf:levtype",
"ecmwf:param",
"ecmwf:step",
"ecmwf:stream"
],
"title": "STAC queryables for DEDL HDA STAC API.",
"type": "object"
}
One of the available filters is the parameter name. By adding the selected parameterID to the previous request to the queryables endpoint, we can retrieve the specific set of filters that apply to that parameter.
The available filters—and their possible values—depend on the parameter you choose. For example, the type of vertical levels (e.g., surface sfc, pressure levels pl, or height levels hl) is determined by the selected parameter.
Some filters instead have fixed default values (as shown in the queryables responses above and below). These defaults are displayed for transparency but do not need to be included in the final search request (e.g., ecmwf:class).
response = requests.get(EXTREMES_QUERYABLES_ENDPOINT,params = {"ecmwf:param": var_sel['parameter_ID']})
if response.status_code != 200:
print(response.content)
response.raise_for_status()
#JSON(response.json())
print(json.dumps(response.json(),indent=2)){
"$id": "https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.DT_EXTREMES/queryables",
"$schema": "https://json-schema.org/draft/2019-09/schema",
"additionalProperties": false,
"description": "Queryable names for DEDL HDA STAC API.",
"properties": {
"ecmwf:class": {
"const": "d1",
"default": "d1",
"title": "class",
"type": "string"
},
"ecmwf:dataset": {
"const": "extremes-dt",
"default": "extremes-dt",
"title": "dataset",
"type": "string"
},
"ecmwf:date": {
"enum": [
"20260702",
"20260703",
"20260704",
"20260705",
"20260706",
"20260707",
"20260708",
"20260709",
"20260710",
"20260711",
"20260712",
"20260713",
"20260714",
"20260715",
"20260716",
"20260717",
"20260718",
"20260719",
"20260720",
"20260721",
"20260722",
"20260723",
"20260724",
"20260725",
"20260726",
"20260727"
],
"title": "date",
"type": "string"
},
"ecmwf:expver": {
"const": "0001",
"default": "0001",
"title": "expver",
"type": "string"
},
"ecmwf:levelist": {
"items": {},
"title": "levelist",
"type": "array"
},
"ecmwf:levtype": {
"const": "sfc",
"title": "levtype",
"type": "string"
},
"ecmwf:param": {
"default": [
"164"
],
"items": {
"enum": [
"134",
"136",
"137",
"151",
"164",
"165",
"166",
"167",
"168",
"228029",
"228050",
"228218",
"228219",
"228221",
"228235",
"235",
"260015",
"3020",
"31",
"34",
"78"
],
"type": "string"
},
"title": "param",
"type": "array"
},
"ecmwf:step": {
"items": {
"enum": [
"0",
"1",
"10",
"11",
"12",
"13",
"14",
"15",
"16",
"17",
"18",
"19",
"2",
"20",
"21",
"22",
"23",
"24",
"25",
"26",
"27",
"28",
"29",
"3",
"30",
"31",
"32",
"33",
"34",
"35",
"36",
"37",
"38",
"39",
"4",
"40",
"41",
"42",
"43",
"44",
"45",
"46",
"47",
"48",
"49",
"5",
"50",
"51",
"52",
"53",
"54",
"55",
"56",
"57",
"58",
"59",
"6",
"60",
"61",
"62",
"63",
"64",
"65",
"66",
"67",
"68",
"69",
"7",
"70",
"71",
"72",
"73",
"74",
"75",
"76",
"77",
"78",
"79",
"8",
"80",
"81",
"82",
"83",
"84",
"85",
"86",
"87",
"88",
"89",
"9",
"90",
"91",
"92",
"93",
"94",
"95",
"96"
],
"type": "string"
},
"title": "step",
"type": "array"
},
"ecmwf:stream": {
"const": "oper",
"title": "stream",
"type": "string"
},
"ecmwf:time": {
"default": "0000",
"items": {
"const": "0000",
"type": "string"
},
"title": "time",
"type": "array"
},
"ecmwf:type": {
"const": "fc",
"default": "fc",
"title": "type",
"type": "string"
},
"datetime": {
"title": "Date and Time",
"description": "The searchable date/time of the assets, in UTC (Formatted in RFC 3339) ",
"type": [
"string",
"null"
],
"format": "date-time",
"pattern": "(\\+00:00|Z)$"
}
},
"required": [
"ecmwf:date",
"ecmwf:levtype",
"ecmwf:step",
"ecmwf:stream"
],
"title": "STAC queryables for DEDL HDA STAC API.",
"type": "object"
}
From the response above, we extract the levellist, step, and stream parameters required to build the request.
It is also possible to check data availability using the running dates provided by Aviso. This helps verify which dates can be queried before submitting the final request.
# the following code will display a dropdown selector
# levtype parameter tells us if the selected parameter is on a single level or surface, sfc, or if it is a pressure level parameter (pl) or a height level parameter (hl)
levtype_info = response.json()['properties'].get("ecmwf:levtype", {})
if "const" in levtype_info:
levtype_values = [levtype_info["const"]]
elif "enum" in levtype_info:
levtype_values = levtype_info["enum"]
else:
levtype_values = []
# 1) levtype selector also if only one level exists;
var_sel["levtype"] = levtype_values[0]
out_levtype_dd = widgets.Output()
levtype_dd = widgets.Dropdown(
options=levtype_values,
value=levtype_values[0],
description="select the desired levtype:"
)
display(levtype_dd, out_levtype_dd)
levtype_dd.observe(refresh_levtype, names="value")
In the cell below, we use the Queryables API again to retrieve the available level values corresponding to the selected level type and parameter.
The values returned in the response are then used to build (if applicable) the corresponding dropdown selector.
#let's use again the queryables API to fetch the available parameters for the selected level type and parameter
response = requests.get(EXTREMES_QUERYABLES_ENDPOINT,params = {"ecmwf:param": var_sel['parameter_ID'],"ecmwf:levtype": var_sel["levtype"]})
if response.status_code != 200:
print(response.content)
response.raise_for_status()
# levlist parameter gives us the list of availables levels if the parameter leveltype is a pressure level parameter (pl) or a height level parameter (hl) we can get the list of availables levels
values_lev=[]
values_lev_info = response.json()['properties'].get("ecmwf:levelist", {})
is_level_const=True
if "const" in values_lev_info:
values_lev = [values_lev_info['const']]
elif("enum" in values_lev_info and var_sel['levtype'] in ["hl", "pl"]):
values_lev = values_lev_info["enum"]
#is_level_const=False
#workaround waiting for DSD-1570, levellist is indicated as a string
is_level_const=True
values_step=response.json()['properties'].get("ecmwf:step")
var_sel["steplist"] = values_step['items']["enum"]
stream=response.json()['properties'].get("ecmwf:stream")
var_sel["stream"] = stream["const"]
timed=response.json()['properties'].get("ecmwf:time")["items"]
var_sel["time"] = timed["const"]
values_dates=response.json()['properties'].get("ecmwf:date")
var_sel["dates"] = values_dates["enum"]
#JSON(response.json())
print(json.dumps(response.json(),indent=2)){
"$id": "https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.DT_EXTREMES/queryables",
"$schema": "https://json-schema.org/draft/2019-09/schema",
"additionalProperties": false,
"description": "Queryable names for DEDL HDA STAC API.",
"properties": {
"ecmwf:class": {
"const": "d1",
"default": "d1",
"title": "class",
"type": "string"
},
"ecmwf:dataset": {
"const": "extremes-dt",
"default": "extremes-dt",
"title": "dataset",
"type": "string"
},
"ecmwf:date": {
"enum": [
"20260702",
"20260703",
"20260704",
"20260705",
"20260706",
"20260707",
"20260708",
"20260709",
"20260710",
"20260711",
"20260712",
"20260713",
"20260714",
"20260715",
"20260716",
"20260717",
"20260718",
"20260719",
"20260720",
"20260721",
"20260722",
"20260723",
"20260724",
"20260725",
"20260726",
"20260727"
],
"title": "date",
"type": "string"
},
"ecmwf:expver": {
"const": "0001",
"default": "0001",
"title": "expver",
"type": "string"
},
"ecmwf:levelist": {
"items": {},
"title": "levelist",
"type": "array"
},
"ecmwf:levtype": {
"const": "sfc",
"default": "sfc",
"title": "levtype",
"type": "string"
},
"ecmwf:param": {
"default": [
"164"
],
"items": {
"enum": [
"134",
"136",
"137",
"151",
"164",
"165",
"166",
"167",
"168",
"228029",
"228050",
"228218",
"228219",
"228221",
"228235",
"235",
"260015",
"3020",
"31",
"34",
"78"
],
"type": "string"
},
"title": "param",
"type": "array"
},
"ecmwf:step": {
"items": {
"enum": [
"0",
"1",
"10",
"11",
"12",
"13",
"14",
"15",
"16",
"17",
"18",
"19",
"2",
"20",
"21",
"22",
"23",
"24",
"25",
"26",
"27",
"28",
"29",
"3",
"30",
"31",
"32",
"33",
"34",
"35",
"36",
"37",
"38",
"39",
"4",
"40",
"41",
"42",
"43",
"44",
"45",
"46",
"47",
"48",
"49",
"5",
"50",
"51",
"52",
"53",
"54",
"55",
"56",
"57",
"58",
"59",
"6",
"60",
"61",
"62",
"63",
"64",
"65",
"66",
"67",
"68",
"69",
"7",
"70",
"71",
"72",
"73",
"74",
"75",
"76",
"77",
"78",
"79",
"8",
"80",
"81",
"82",
"83",
"84",
"85",
"86",
"87",
"88",
"89",
"9",
"90",
"91",
"92",
"93",
"94",
"95",
"96"
],
"type": "string"
},
"title": "step",
"type": "array"
},
"ecmwf:stream": {
"const": "oper",
"title": "stream",
"type": "string"
},
"ecmwf:time": {
"default": "0000",
"items": {
"const": "0000",
"type": "string"
},
"title": "time",
"type": "array"
},
"ecmwf:type": {
"const": "fc",
"default": "fc",
"title": "type",
"type": "string"
},
"datetime": {
"title": "Date and Time",
"description": "The searchable date/time of the assets, in UTC (Formatted in RFC 3339) ",
"type": [
"string",
"null"
],
"format": "date-time",
"pattern": "(\\+00:00|Z)$"
}
},
"required": [
"ecmwf:date",
"ecmwf:step",
"ecmwf:stream"
],
"title": "STAC queryables for DEDL HDA STAC API.",
"type": "object"
}
In this step, we build the dropdown selectors based on the retrieved values.
# ensure a variable was selected earlier ---
if not var_sel or not var_sel.get("name"):
raise ValueError("Please select a variable by narrowing down the list in the cell above!")
ws = []
levels_ms = None
steps_dd = None
# 2) Levels selector only if levelist exists;
levels = []
if (values_lev):
levels_ms = widgets.SelectMultiple(
options=values_lev,
value=(), # nothing preselected
rows=min(10, max(5, len(levels))),
description="Levels:"
)
ws.append(levels_ms)
# 3) steps selector only if step exists;
if values_step:
ws.append(steps_dd)
steps_dd = widgets.Dropdown(
options=var_sel.get("steplist"),
value=var_sel.get("steplist")[0],
description="step:"
)
ws.append(steps_dd)
out = widgets.Output()
# Wire events
if levtype_dd is not None:
levtype_dd.observe( refresh_step_levels, names="value")
if levels_ms is not None:
levels_ms.observe( refresh_step_levels, names="value")
if steps_dd is not None:
steps_dd.observe( refresh_step_levels, names="value")
display(*(ws + [out]))
refresh_step_levels()We have now selected all the information needed to perform a data request
Datetime Selection¶
Extreme DT data is available only within specific time windows — namely, the last 15 days relative to the current date.
To verify that the most recent 15 days of data are actually available, you can use the ECMWF Aviso package (Examples demonstrating this check can be found in the following notebooks/scripts: https://github.com/destination-earth/DestinE-DataLake-Lab/blob/main/HDA/DestinE Digital Twins/ExtremeDT-dataAvailability.ipynb or aviso
This data‑availability check is also performed internally by HDA. The results are included in the queryables response. We extracted and stored this information earlier, and we will now use it to build the dates selector below.
####################################
# The following code set date_from to 15 days ago and date_to to today
# Get the current date and time in UTC
current_date = datetime.utcnow()
# Calculate the date 15 days before the current date
date_15_days_ago = current_date - timedelta(days=14)
####################################
# The following code compares the availability dates returned by the queryables endpoint with the 15‑day validity window, ensuring we derive the correct date range for querying Extreme DT data.
# Convert dates strings to datetime objects
dates = [datetime.strptime(d, "%Y%m%d") for d in var_sel["dates"]]
#Filter dates inside [date_from, date_to]
dates_in_range = [d for d in dates if date_15_days_ago <= d <= current_date]
####################################
# The following code creates the dates selector for our data request
from ipywidgets import Label
# Create dropdown to select scenario
# Create date picker widgets
start_date_picker = widgets.DatePicker(description='Start Date:', disabled=False)
start_date_picker = widgets.Dropdown(
options=[(d.isoformat(), d) for d in dates_in_range],
description="Start Date:",
style={"description_width": "initial"},
)
# Display widgets
display(Label("Dates can be selected only within the current Extremes DT data‑availability window."), start_date_picker)date_selected = start_date_picker.value.date()
print("Selected date:", date_selected)
Selected date: 2026-07-27
Order and Download - Order and Access Extreme DT data¶
Obtain Authentication Token¶
To perform our request we need to be authenticated. Below to request of an authentication token.
DESP_USERNAME = input("Please input your DESP username: ")
DESP_PASSWORD = getpass("Please input your DESP password: ")
auth = deauth.AuthHandler(DESP_USERNAME, DESP_PASSWORD)
access_token = auth.get_token()
if access_token is not None:
print("DEDL/DESP Access Token Obtained Successfully")
else:
print("Failed to Obtain DEDL/DESP Access Token")
auth_headers = {"Authorization": f"Bearer {access_token}"}Please input your DESP username: eum-dedl-user
Please input your DESP password: ········
DEDL/DESP Access Token Obtained Successfully
Response code: 200
DEDL/DESP Access Token Obtained Successfully
Check if DT access is granted¶
If DT access is not granted, you will not be able to execute the rest of the notebook.
auth.is_DTaccess_allowed(access_token)TrueHDA data request with the made selections¶
Use the chosen parameters to construct an HDA Climate DT data request, then output the filters that were created.
filter_params = {
"ecmwf:type": "fc", # fixed forecasted fields
"ecmwf:levtype": var_sel["levtype"],
"ecmwf:param": [str(var_sel["parameter_ID"])],
"ecmwf:stream": str(var_sel["stream"]),
"ecmwf:step": [str(var_sel["steps"])],
"ecmwf:time": [str(var_sel["time"])]
}
# Check if levelist is empty and/or constant and adjust the request
if (var_sel.get("levels")):
filter_params["ecmwf:levelist"]=var_sel['levels']
if is_level_const:
filter_params["ecmwf:levelist"]=var_sel['levels'][0]
hdaFilters = {
key: {"eq": value}
for key, value in filter_params.items()
}
print("HDA search request body for our data of interest:")
#JSON(hdaFilters)
print(json.dumps(hdaFilters,indent=2))HDA search request body for our data of interest:
{
"ecmwf:type": {
"eq": "fc"
},
"ecmwf:levtype": {
"eq": "sfc"
},
"ecmwf:param": {
"eq": [
"164"
]
},
"ecmwf:stream": {
"eq": "oper"
},
"ecmwf:step": {
"eq": [
"96"
]
},
"ecmwf:time": {
"eq": [
"0000"
]
}
}
Filtering¶
Asynchronous dataset searches—such as those for Digital Twins—return exactly one item.
This item provides both the correct API endpoint and the complete request body needed to execute the data order.
#Sometimes requests to polytope get timeouts, it is then convenient define a retry strategy
retry_strategy = Retry(
total=5, # Total number of retries
status_forcelist=[500, 502, 503, 504], # List of 5xx status codes to retry on
allowed_methods=["GET",'POST'], # Methods to retry
backoff_factor=1 # Wait time between retries (exponential backoff)
)
# Create an adapter with the retry strategy
adapter = HTTPAdapter(max_retries=retry_strategy)
# Create a session and mount the adapter
session = requests.Session()
session.mount("https://", adapter)
response = session.post(HDA_STAC_ENDPOINT+"/search", headers=auth_headers, json={
"collections": [COLLECTION_ID],
"datetime": f'{date_selected.isoformat()}T00:00Z',
"query": hdaFilters
})
if(response.status_code!= 200):
(print(response.text))
response.raise_for_status()
product = response.json()["features"][0]
#JSON(product)
print(json.dumps(product,indent=2)){
"type": "Feature",
"assets": {},
"id": "DT_EXTREMES_ORDERABLE_79a7b33289c735b78fc727de607e7088598f2f1d",
"geometry": {
"type": "Polygon",
"coordinates": [
[
[
180.0,
-90.0
],
[
180.0,
90.0
],
[
-180.0,
90.0
],
[
-180.0,
-90.0
],
[
180.0,
-90.0
]
]
]
},
"bbox": [
-180.0,
-90.0,
180.0,
90.0
],
"collection": "EO.ECMWF.DAT.DT_EXTREMES",
"stac_version": "1.1.0",
"properties": {
"datetime": "2026-07-27T00:00:00.000Z",
"end_datetime": "2026-07-27T00:00:00.000Z",
"start_datetime": "2026-07-27T00:00:00.000Z",
"title": "DT_EXTREMES_ORDERABLE_79a7b33289c735b78fc727de607e7088598f2f1d",
"ecmwf:class": "d1",
"ecmwf:dataset": "extremes-dt",
"ecmwf:date": "20260727/to/20260727",
"ecmwf:expver": "0001",
"ecmwf:levtype": "sfc",
"ecmwf:param": [
"164"
],
"ecmwf:step": [
"96"
],
"ecmwf:stream": "oper",
"ecmwf:time": [
"0000"
],
"ecmwf:type": "fc",
"order:status": "orderable",
"product:type": "extremes-dt",
"federation:backends": [
"dedt_lumi"
],
"providers": [
{
"name": "dedt_lumi",
"roles": [
"host"
]
}
]
},
"stac_extensions": [
"https://stac-extensions.github.io/product/v1.0.0/schema.json",
"https://stac-extensions.github.io/order/v1.1.0/schema.json"
],
"links": [
{
"rel": "retrieve",
"type": "application/geo+json",
"href": "https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.DT_EXTREMES/order",
"method": "POST",
"title": "Retrieve",
"body": {
"class": "d1",
"dataset": "extremes-dt",
"date": "20260727/to/20260727",
"expver": "0001",
"levtype": "sfc",
"param": [
"164"
],
"step": [
"96"
],
"stream": "oper",
"time": [
"0000"
],
"type": "fc"
}
},
{
"rel": "collection",
"type": "application/json",
"href": "https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.DT_EXTREMES",
"title": "Weather-Induced Extremes Digital Twin (Extremes DT)"
},
{
"rel": "self",
"type": "application/geo+json",
"href": "https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.DT_EXTREMES/items/DT_EXTREMES_ORDERABLE_79a7b33289c735b78fc727de607e7088598f2f1d",
"title": "Original item link"
}
]
}
The single item returned (above) contains:
The product id: “DT_CLIMATE_ADAPTATION_ORDERABLE_...”, that is a placeholder, its name contains the term “ORDERABLE”.
The storage:tier that indicates that the product is “offline”
The order:status that indicates that the product is “orderable”
Request params used for the order extracted from the search result
link = next((l for l in product.get('links', []) if l.get("rel") == "retrieve"), None)
if link:
href = link.get("href")
body = link.get("body") # optional: depends on extension
print("order endpoint:", href)
print("order body, same as the polytope format:")
print(json.dumps(body, indent=4))
else:
print(f"No link with rel='{target_rel}' found")
order endpoint: https://hda.data.destination-earth.eu/stac/v2/collections/EO.ECMWF.DAT.DT_EXTREMES/order
order body, same as the polytope format:
{
"class": "d1",
"dataset": "extremes-dt",
"date": "20260727/to/20260727",
"expver": "0001",
"levtype": "sfc",
"param": [
"164"
],
"step": [
"96"
],
"stream": "oper",
"time": [
"0000"
],
"type": "fc"
}
Order data¶
We have now all the information to order the data.
From the search results we know that the product is orderable and offline, we then need to order the product we searched for.
response = session.post(href, json=body, headers=auth_headers)
if response.status_code != 200:
print(response.content)
response.raise_for_status()
ordered_item = response.json()
product_id = ordered_item["id"]
storage_tier = ordered_item["properties"].get("storage:tier", "online")
order_status = ordered_item["properties"].get("order:status", "unknown")
federation_backend = ordered_item["properties"].get("federation:backends", [None])[0]
print(f"Product ordered: {product_id}")
print(f"Provider: {federation_backend}")
print(f"Order status: {order_status}") Product ordered: 01ejwrk982yfn6r005eavk8cj5
Provider: dedt_lumi
Order status: succeeded
Poll the API until product is ready¶
We request the product itself to get an update of its status.
#timeout and step for polling (sec)
TIMEOUT = 300
STEP = 1
ORDER_STATUS = "succeeded"
self_url = f"{HDA_STAC_ENDPOINT}/collections/{COLLECTION_ID}/items/{product_id}"
item = {}
for i in range(0, TIMEOUT, STEP):
print(f"Polling {i + 1}/{TIMEOUT // STEP}")
response = session.get(self_url, headers=auth_headers)
if response.status_code != 200:
print(response.content)
response.raise_for_status()
item = response.json()
print(item["properties"].get("order:status"))
status = item["properties"].get("order:status")
if status == ORDER_STATUS:
download_url = item["assets"]["downloadLink"]["href"]
print("Product is ready to be downloaded.")
print(f"Asset URL: {download_url}")
break
time.sleep(STEP)
else:
order_status = item["properties"].get("order:status", "unknown")
print(f"We could not download the product after {TIMEOUT // STEP} tries. Current order status is {order_status}")
Polling 1/300
succeeded
Product is ready to be downloaded.
Asset URL: https://hda-download.lumi.data.destination-earth.eu/data/dedt_lumi/EO.ECMWF.DAT.DT_EXTREMES/01ejwrk982yfn6r005eavk8cj5/downloadLink
Download¶
response = requests.get(download_url, stream=True, headers=auth_headers)
response.raise_for_status()
content_disposition = response.headers.get('Content-Disposition')
total_size = int(response.headers.get("content-length", 0))
if content_disposition:
filename = content_disposition.split('filename=')[1].split('"')[1]
else:
filename = os.path.basename(url)
# Open a local file in binary write mode and write the content
print(f"downloading {filename}")
with tqdm(total=total_size, unit="B", unit_scale=True) as progress_bar:
with open(filename, 'wb') as f:
for data in response.iter_content(1024):
progress_bar.update(len(data))
f.write(data)downloading 01ejwrk982yfn6r005eavk8cj5.grib
57.2MB [00:01, 30.4MB/s]
import earthkit.data
import earthkit.plots
import earthkit.regrid
data = earthkit.data.from_source("file", filename)
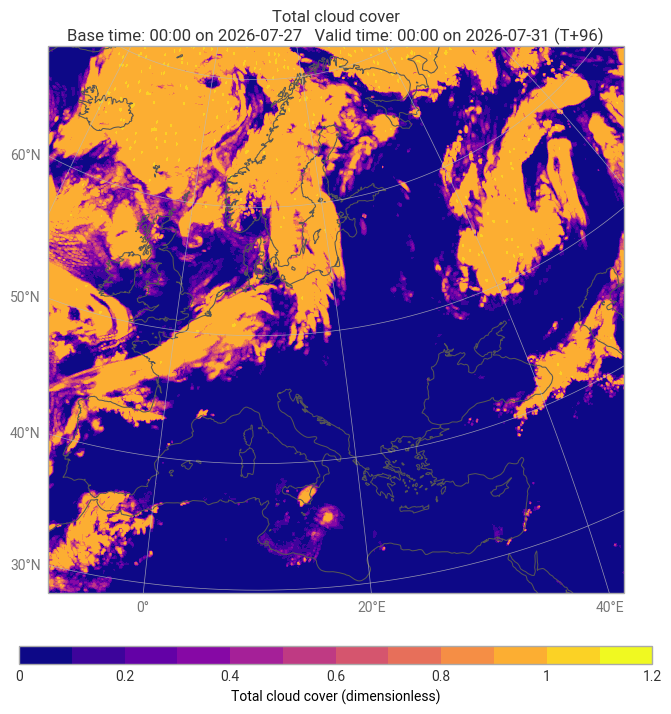
earthkit.plots.quickplot(data, domain="Europe")Regrid specs: in_grid={'grid': 'O2560'}, out_grid={'grid': [0.1, 0.1]}
<earthkit.plots.components.figures.Figure at 0x7f4f2213c310>