GFTS SVVR Software Verification and Validation Report
Introduction
This document describes the progress regarding the Software Verification and Validation Plan (SVVP) of the Global Fish Tracking System (GFTS) use case for the DestinE Platform.
Use Case Description
The GFTS aims to provide a scalable, cloud-based environment for fish track reconstruction, leveraging biologging and environmental data to support marine research and decision-making. The system includes a JupyterHub-based modeling environment and a web-based decision support tool, both integrated with the DestinE Platform.
Backend verification activities
We have established a GitHub repository ([https://github.com/destination-earth/DestinE_ESA_GFTS]) to manage the development and verification of the GFTS. The repository includes a comprehensive set of GitHub Actions workflows to automate building, testing, linting, and deployment processes, ensuring the reliability and quality of the system. To enhance transparency, we have added badges to the repository’s [README.md] file to display the pass/fail status of key workflows, and detailed logs of all GitHub Actions runs are publicly accessible at [https://github.com/destination-earth/DestinE_ESA_GFTS/actions].
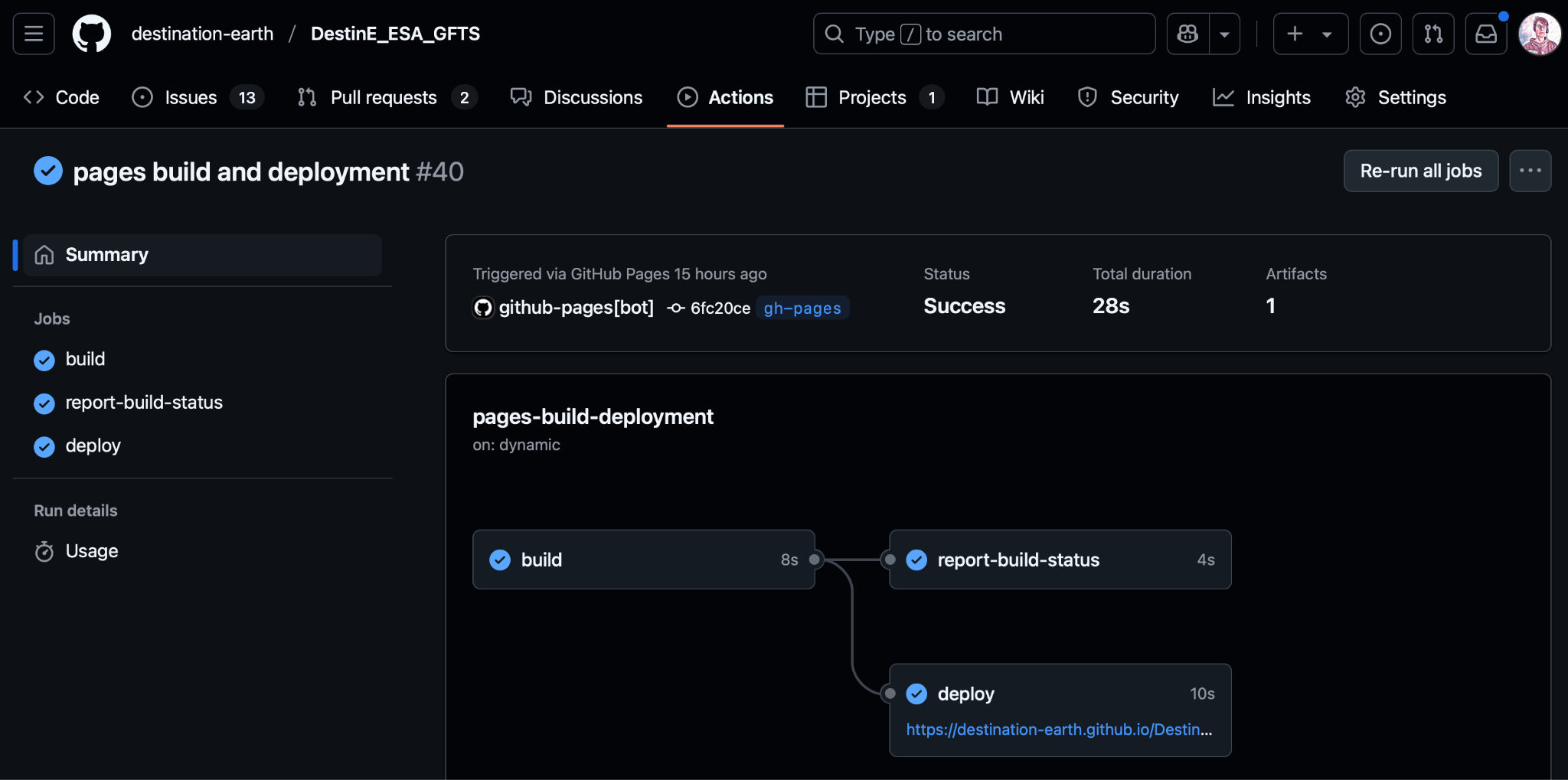
The image above shows a screenshot of the GitHub actions being executed and reported on. Below is an overview of the implemented workflows and their roles in verification:
GitHub Actions Workflows
Linting with Pre-Commit (pre-commit.yaml)
Purpose: Ensures code quality and consistency by running pre-commit hooks on pull requests.
Activities:
Installs and runs pre-commit to check code formatting, style, and potential errors.
Caches pre-commit hooks to improve performance.
Provides detailed feedback on failures, including auto-formatting diffs, to guide developers in resolving issues.
Verification Role: Enforces coding standards, reducing bugs and maintaining a clean codebase.
Documentation Deployment (deploy.yaml)
Purpose: Automates the building and deployment of GFTS documentation as a Jupyter Book.
Activities:
Triggers on pushes to the main branch for changes in the docs/ directory.
Uses a Conda environment to build the Jupyter Book.
Deploys the generated HTML to the gh-pages branch using GitHub Pages.
Badge: Displays the workflow status in the README.md: GFTS Jupyter Book
Verification Role: Ensures that documentation is consistently updated and accessible, supporting user and developer verification of system functionality.
Docker Image Testing (test-image.yaml)
Purpose: Validates Docker images for the JupyterHub environment when changes are made to Conda or pip dependencies.
Activities:
Triggers on pull requests affecting the gfts-track-reconstruction/jupyterhub/images/user directory.
Builds the Docker image using Chartpress without pushing to the registry, ensuring the image is functional.
Verifies that dependencies are correctly installed and compatible.
Verification Role: Confirms that changes to the environment do not break the JupyterHub deployment, ensuring stability.
JupyterHub Deployment (deploy-hub.yaml)
Purpose: Automates the deployment of the JupyterHub environment to OVH cloud infrastructure.
Activities:
Triggers on pushes to main or test-deploy branches or manually via workflow dispatch.
Installs dependencies, kubectl, and Helm.
Unlocks git-crypt secrets for secure access to configuration files.
Builds and pushes Docker images using Chartpress.
Deploys the JupyterHub environment with Helm, configuring compute and storage (e.g., S3 buckets for user groups).
Supports testing multiple Docker images for flexibility.
Badge: Displays the workflow status in the README.md: GFTS Jupyter Hub
Verification Role: Ensures that the JupyterHub environment is correctly configured, scalable, and operational, meeting requirements like R101 (Scalable JupyterHub environment).
Web Application Deployment (deploy-webapp.yaml)
Purpose: Automates the deployment of the GFTS web application service to Kubernetes.
Activities:
Triggers on pushes to the main branch for changes in the webapp/ directory or manually via workflow dispatch.
Unlocks git-crypt secrets for secure configuration.
Builds and pushes the webapp Docker image to the OVH container registry, incorporating environment variables (e.g., Mapbox token).
Updates Helm dependencies and deploys the webapp to Kubernetes using Helm.
Verification Role: Verifies that the web application is correctly built, deployed, and accessible, supporting the decision support tool’s development.
Transparency and Logging
GitHub Actions Badges: The README.md file includes badges (see image below) for the deploy.yaml and deploy-hub.yaml workflows, providing a visual indication of their pass/fail status. These badges enhance transparency by allowing stakeholders to quickly assess the health of critical workflows.
Detailed Logs: All GitHub Actions runs, including logs for linting, testing, and deployment workflows, are publicly accessible at https://github.com/destination-earth/DestinE_ESA_GFTS/actions. These logs provide detailed insights into the execution of each workflow, facilitating debugging and verification. Below is a view of the Github action tab in the Github repository showing a successful run of the deployment of the documentation.
Modeling environment verification
To ensure quality control of our JupyterHub deployments on the cloud, we implement a CI/CD pipeline that includes automated testing, validation, and deployment processes. This pipeline leverages the GitHub Actions workflows described above, which are triggered by code changes, e.g. a pull request or pushes. For our JupyterHub environment, we use Chartpress, a tool that automates the building and publishing of Docker images for Helm charts. The [test-image.yaml] and [deploy-hub.yaml] Github workflows ensure that images are built, tested, and deployed consistently, reducing manual intervention and errors. The pass/fail status of these workflows is visible via badges in the [README.md], and detailed logs are available at [https://github.com/destination-earth/DestinE_ESA_GFTS/actions], providing transparency into the verification process. When changes are made, the pipeline automatically builds these images, installs and updates dependencies, and ensures that all configurations pass predefined checks before deployment. Chartpress ensures that our Helm charts and associated images are consistently built and deployed, reducing manual intervention and the likelihood of errors. By combining this with version control, incremental deployments, and cloud monitoring, we maintain a high level of stability and reliability in our JupyterHub environments, ensuring seamless upgrades and operational integrity across cloud platforms.
The table below outlines the verification activities for the modeling environment
ID Requirement Activity
R101 Scalable Jupyter-Hub environment Deployment and verification automated through Chartpress and GitHub Actions (deploy-hub.yaml, test-image.yaml).
R102 Access Copernicus Marine Data Copernicus marine data has been added to our own object storage and its completeness has been confirmed.
R103 Seabass biologging data Biologging data has been uploaded to our own object storage and its completeness has been confirmed.
R105 Fish track model output Fish track output is inspected visually by scientists to ensure correctness of the results. Iterations are being carried out correcting for unexpected modeling output.
Decision support tool verification activities
We have established a GitHub repository ([https://github.com/developmentseed/gfts]) to manage the development and verification of the GFTS decision support tool. We leverage GitHub Actions to automate software verification and deployment processes through two primary workflows: Checks and Deploy GitHub Pages. These workflows ensure consistent validation of code quality and streamline the deployment of frontend assets.
Checks Workflow
This workflow runs automatically for all branches except main. The project uses branch protection rules to ensure that code changes are merged only after successful verification through pull requests.
The workflow is structured into three primary jobs:
prep (Preparation Job):
Installs Node.js based on the .nvmrc file.
Restores and caches node_modules to optimize performance.
Installs project dependencies using yarn. Skips execution if the pull request is still marked as a draft.
lint (Code Quality Check):
Runs only after the prep job completes successfully.
Performs static analysis using the project’s configured linter (yarn lint).
Ensures code adheres to the defined formatting and style rules.
test (Automated Testing):
Also depends on the prep job.
Executes the project’s test suite (yarn test) to verify functionality and detect regressions.
The lint and test jobs are executed in parallel, allowing for faster feedback.
Deploy GitHub Pages Workflow
This workflow is triggered only when code is pushed to the main branch, reflecting the intention to deploy production-ready artifacts.
It consists of two jobs:
build:
Checks out the codebase and installs dependencies.
Builds the project (yarn build), typically producing static frontend files in a dist directory.
Uses caching for both dependencies (node_modules) and build output (dist) to accelerate subsequent runs.
deploy:
Depends on the successful completion of the build job.
Restores the cached build output.
Uses the [JamesIves/github-pages-deploy-action] to publish the contents of the dist folder to the gh-pages branch, which is then served via GitHub Pages.
Additional Features
Environment Variables: The deployment workflow uses secrets and environment variables (e.g., PUBLIC_URL, DATA_API, MAPBOX_TOKEN) to configure the build and deployment process dynamically.
Concurrency Control: Both workflows use concurrency settings to ensure that only the latest run per branch is executed, canceling any in-progress jobs for the same reference.
Permissions: The workflows are granted appropriate permissions (e.g., contents: write) to perform deployments.
Validation activities
For our use case we have validated that the outcomes of our efforts match the intended use case. For this we have actively participated in the relevant communities and were in continuous contact with potential users. Our work had a clear product focus throughout the project where user needs were put at the forefront of development. We worked with potential users to validate that what we were building is meeting their needs.
Modeling environment validation
During multiple conferences we have interacted with multiple stakeholders of the GFTS project, as well as several potential users of the GFTS fish track reconstruction environment. This has informed multiple decisions on how to set up the architecture. The feedback from stakeholders within the Destination Earth ecosystem, and the increased learning about the concrete capabilities of the DestinE Platform has resulted in a revised assessment of how operationalized the fish track reconstruction. We have packaged the environment in a stack that can easily be reproduced in Jupyter hub environments, such as the environment that has been offered by the DestinE platform.
We also were and will continue to be in conversations with the biologging community to understand their needs, for example the European Tracking Network (ETN).
To support user validation and replication, we have provided a comprehensive Docker and Conda environment setup in the repository at:
This includes a Dockerfile based on the pangeo-notebook image (see [https://github.com/pangeo-data/pangeo-docker-images]), installing essential dependencies and packages like pangeo-fish and xhealpixify. The Conda environment is defined in conda-requirements.txt (e.g., copernicusmarine, movingpandas), and pip dependencies are listed in requirements.txt. A jupyter_server_config.py file configures the Jupyter server for idle timeouts and content management. These resources, combined with the GFTS documentation (deployed via deploy.yaml), enable end-users to replicate the environment locally or on compatible platforms and test fish track reconstruction workflows, such as those using the pangeo-fish package, although access to DestinE Platform data is required for full functionality.
Decision support tool validation
We have been in continuous contact with our test users to obtain feedback on the design and features of the interface. This feedback was integrated into the web application in the progressive updates that we were pushing to the GitHub repository throughout the project. This feedback loop was essential to validate that our decision support tool adds value to the end user.
Scientific validation of modeling results
During this project, we have iteratively improved the pangeo-fish software and applied multiple different versions of the software to the fish track data. The interface contains the results from the most recent iteration, which are also the most reliable results .There is no quantitative procedure to validate tracks at this point, but that is something we might consider developing in the future. The fish tracks are reviewed manually and unrealistic tracks are discarded based on expert knowledge and results obtained from our research paper “[Seasonal migration, site fidelity, and population structure of European seabass]”.